For commercial auto underwriters
Know before you bind.
Behavioural risk intelligence from your fleets' video. 5× more predictive than telematics.

See risk emerge — and how the driver responds.
Behavioural risk intelligence from your fleets' video. 5× more predictive than telematics.
See risk emerge — and how the driver responds.
Our vision transformer reads forward-facing footage. The score reads zero during safe driving. It rises as danger develops — about when an alert driver would notice.
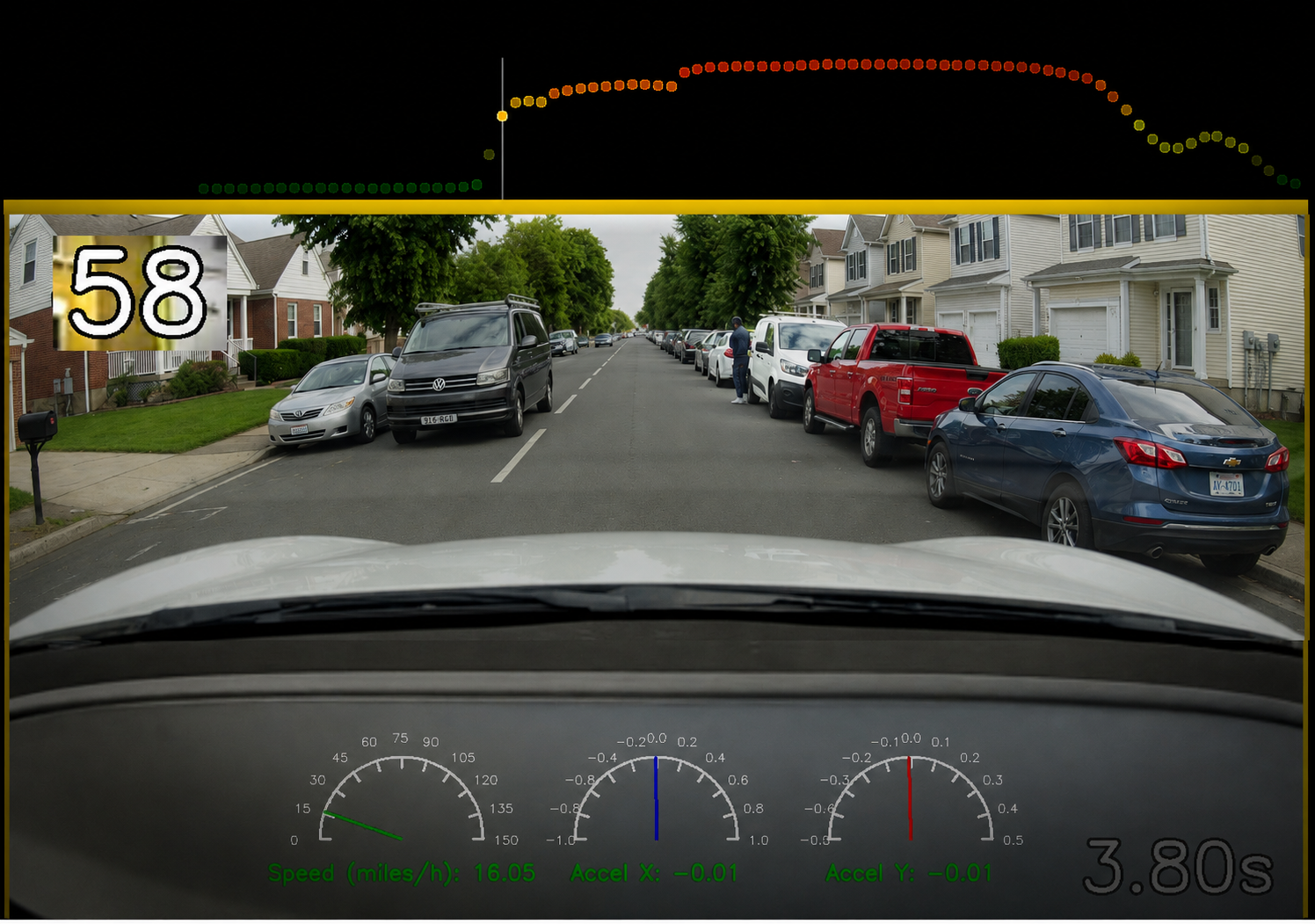
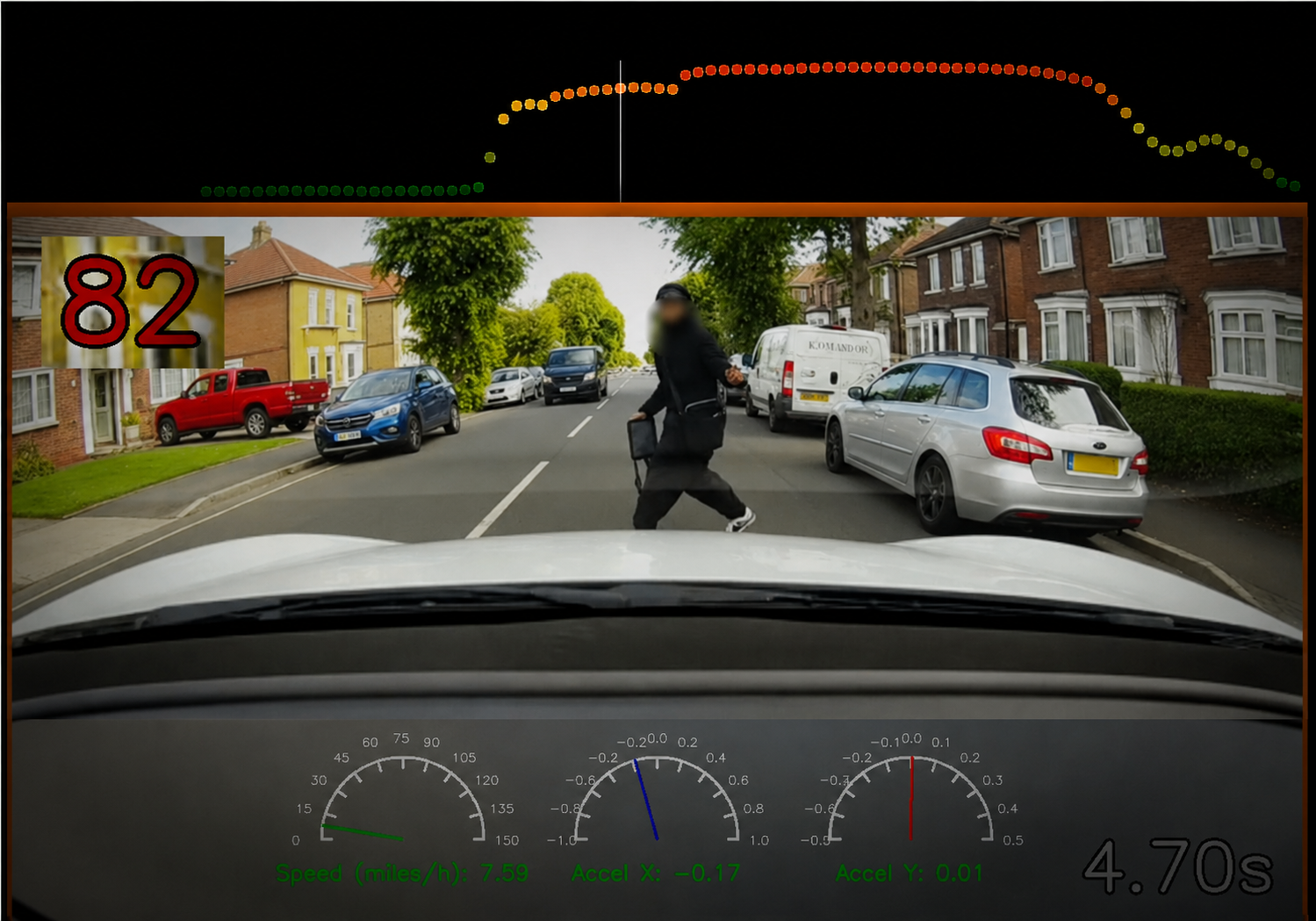
Synthetic renderings of a real event captured by a fleet dashcam and scored by VisionScore. The risk score and timing are real; the scene is anonymised.
A per-driver behavioural score on top of your existing rating factors. Tell safe fleets and safe drivers from risky ones — with data telematics can't generate. Tighten your loss ratio without raising rates on the good ones.
Continuous monitoring after bind. Spot the drivers carrying most of the claim severity. Coaching response feeds back into renewal. Differentiate coachable fleets from the uncoachable.
Real-time crash detection. Vehicle, location, severity, and behavioural context delivered to claims within seconds of impact. Catches the low-speed and vulnerable-road-user events accelerometer-based FNOL misses.
The fleet's existing dashcam system provides the foundations — the trigger and the event videos. VisionScore sits on top and adds risk understanding: if risk emerged, and did the driver respond well to it.
| Existing system gives you | VisionScore adds |
|---|---|
| Vehicle motion — accelerometer, GPS | How much risk there is in the scene |
| Event triggers (harsh brake, hard turn, sudden swerve) | Frame-by-frame risk score as it develops, before the event fires |
| All triggered events, including false positives | Filter out false positives and highlight the most dangerous events |
| The crashes the accelerometer caught | The crashes other systems miss — low-speed, vulnerable road user |
| The extreme tail of risk | The broad middle, where most claims occur |
Same fleet. Same dashcam. Same telematics stack.
A different signal on top — one that helps you understand the quality of the fleet's drivers.
VisionScore delivers a threefold improvement over traditional predictive detection for at-fault claims.*
Live and scaled with the largest European gig economy leasing fleet: 10,000 vehicles. Delivering a 30% claims frequency improvement.
Waylens has licensed VisionScore, rolling it out across 150,000 cameras in North America. Cloud-based, no new hardware. Crash confirmation and FNOL within minutes of impact.
* The VisionScore technology has undergone independent review by Dr Neale Kinnear, former head of behavioural insights at Aon, and Dr Johnathon Ehsani, associate professor at Johns Hopkins University.
Book a 30-minute walkthrough. We'll score a sample fleet from your book and show you what you're missing. Three-month pilots, single API key, no new hardware.